

随着容器的火热发展,数人云 越来越多的客户对容器网络特性要求也开始越来越高,比如:
一容器一IP
多主机容器互联
网络隔离
ACL
对接 SDN 等等
这次主要跟大家聊聊 Docker 的网络方案,首先是现有容器网络方案介绍, 接下来重点讲解 Calico 的特性及技术点,作为引申和对比再介绍下 Contiv 的特性, 最后给出对比测试结果。
现有的主要 Docker 网络方案
首先简单介绍下现有的容器网络方案,网上也看了好多对比,大家之前都是基于实现方式来分,
隧道方案
通过隧道, 或者说 overlay network 的方式:
Weave,UDP 广播,本机建立新的 BR,通过 PCAP 互通。
Open vSwitch(OVS),基于 VxLAN 和 GRE 协议,但是性能方面损失比较严重。
Flannel,UDP 广播,VxLan。
隧道方案在 IaaS 层的网络中应用也比较多,大家共识是随着节点规模的增长复杂度会提升, 而且出了网络问题跟踪起来比较麻烦,大规模集群情况下这是需要考虑的一个点。
路由方案
还有另外一类方式是通过路由来实现,比较典型的代表有:
Calico,基于 BGP 协议的路由方案,支持很细致的 ACL 控制,对混合云亲和度比较高。
Macvlan,从逻辑和 Kernel层来看隔离性和性能最优的方案,基于二层隔离,所以需要二层路由器支持,大多数云服务商不支持,所以混合云上比较难以实现。
路由方案一般是从 3 层或者 2 层实现隔离和跨主机容器互通的,出了问题也很容易排查。
我觉得 Docker 1.9 以后再讨论容器网络方案,不仅要看实现方式,而且还要看网络模型的“站队”,比如说你到底是要用 Docker 原生的 “CNM”,还是CoreOS,谷歌主推的 “CNI”。
Docker libnetwork Container Network Model (CNM) 阵营
Docker Swarm overlay
Macvlan & IP network drivers
Calico
Contiv (from Cisco)
Docker libnetwork 的优势就是原生,而且和 Docker 容器生命周期结合紧密;缺点也可以理解为是原生,被 Docker “绑架”。
Container Network Interface (CNI) 阵营
Kubernetes
Weave
Macvlan
Flannel
Calico
Contiv
Mesos CNI
CNI 的优势是兼容其他容器技术(e.g. rkt)及上层编排系统(K8s & Mesos),而且社区活跃势头迅猛,Kubernetes 加上 CoreOS 主推;缺点是非 Docker 原生。
而且从上的也可以看出,有一些第三方的网络方案是“脚踏两只船”的, 我个人认为目前这个状态下也是合情理的事儿,但是长期来看是存在风险的, 或者被淘汰,或者被收购。
Calico
接下来重点介绍 Calico,原因是它在 CNM 和 CNI 两大阵营都扮演着比较重要的角色。即有着不俗的性能表现,提供了很好的隔离性,而且还有不错的 ACL 控制能力。
Calico 是一个纯3层的数据中心网络方案,而且无缝集成像 OpenStack 这种 IaaS 云架构,能够提供可控的 VM、容器、裸机之间的 IP 通信。
通过将整个互联网的可扩展 IP 网络原则压缩到数据中心级别,Calico 在每一个计算节点利用 Linux kernel 实现了一个高效的 vRouter 来负责数据转发,而每个 vRouter 通过 BGP 协议负责把自己上运行的 workload 的路由信息像整个 Calico 网络内传播 - 小规模部署可以直接互联,大规模下可通过指定的 BGP route reflector 来完成。
这样保证最终所有的 workload 之间的数据流量都是通过 IP 路由的方式完成互联的。

Calico 节点组网可以直接利用数据中心的网络结构(无论是 L2 或者 L3),不需要额外的 NAT,隧道或者 overlay network。
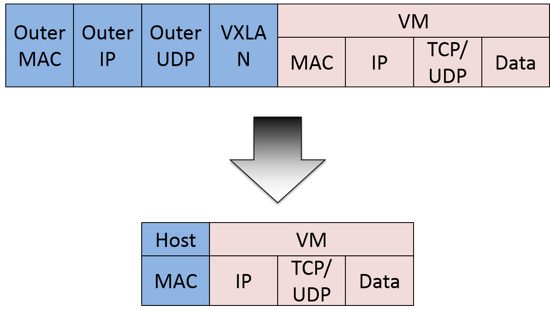
如上图所示,这样保证这个方案的简单可控,而且没有封包解包,节约 CPU 计算资源的同时,提高了整个网络的性能。
此外,Calico 基于 iptables 还提供了丰富而灵活的网络 policy, 保证通过各个节点上的 ACLs 来提供 workload 的多租户隔离、安全组以及其他可达性限制等功能。
Calico 架构
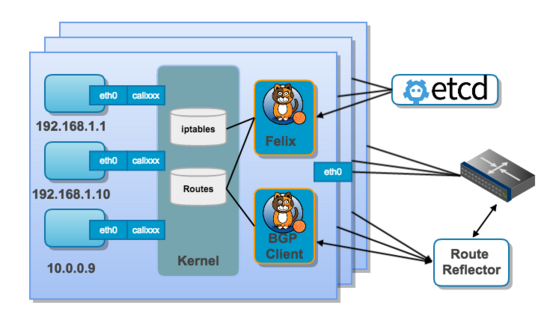
结合上面这张图,我们来过一遍 Calico 的核心组件:
Felix,Calico agent,跑在每台需要运行 workload 的节点上,主要负责配置路由及 ACLs 等信息来确保
endpoint 的连通状态;etcd,分布式键值存储,主要负责网络元数据一致性,确保 Calico 网络状态的准确性;
BGP Client(BIRD), 主要负责把 Felix 写入 kernel 的路由信息分发到当前 Calico 网络,确保
workload 间的通信的有效性;BGP Route Reflector(BIRD), 大规模部署时使用,摒弃所有节点互联的 mesh 模式,通过一个或者多个 BGP
Route Reflector 来完成集中式的路由分发;
Calico Docker network 核心概念
从这里开始我们将“站队” CNM, 通过 Calico Docker libnetwork plugin 的方式来体验和讨论 Calico 容器网络方案。
先来看一下 CNM 模型:
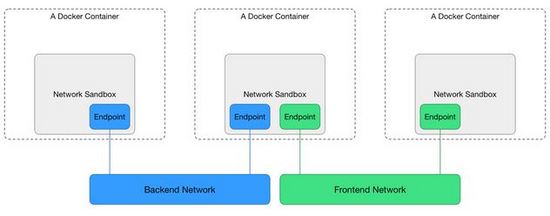
从上图可以知道,CNM 基于3个主要概念:
Sandbox,包含容器网络栈的配置,包括 interface,路由表及 DNS配置,对应的实现如:Linux Network
Namespace;一个 Sandbox 可以包含多个 Network;Endpoint,做为 Sandbox 接入 Network 的介质,对应的实现如:veth pair,TAP;一个 Endpoint
只能属于一个 Network,也只能属于一个 Sandbox;Network,一组可以相互通信的 Endpoints;对应的实现如:Linux bridge,VLAN;Network 有大量
Endpoint 资源组成;
除此之外,CNM 还需要依赖另外两个关键的对象来完成 Docker 的网络管理功能,他们分别是:
NetworkController, 对外提供分配及管理网络的 APIs,Docker libnetwork 支持多个活动的网络
driver,NetworkController 允许绑定特定的 driver 到指定的网络;Driver,网络驱动对用户而言是不直接交互的,它通过插件式的接入来提供最终网络功能的实现;Driver(包括 IPAM) 负责一个
network 的管理,包括资源分配和回收;
有了这些关键的概念和对象,配合 Docker 的生命周期,通过 APIs 就能完成管理容器网络的功能,具体的步骤和实现细节这里不展开讨论了, 有兴趣的可以移步 Github: https://github.com/docker/libn ... gn.md
接下来再介绍两个 Calico 的概念:
Pool, 定义可用于 Docker Network 的 IP 资源范围,比如:10.0.0.0/8 或者 192.168.0.0/16;
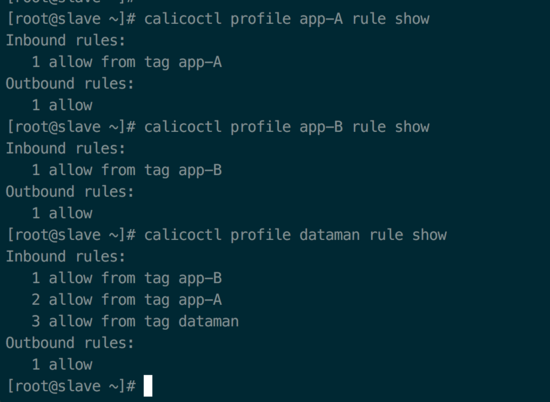
Profile,定义 Docker network Policy 的集合,由 tags 和 rules 组成;每个 Profile
默认拥有一个和 Profile 名字相同的 Tag,每个 Profile 可以有多个 Tag,以 List 形式保存;
Profile 样例:
Inbound rules:1 allow from tag WEB
2 allow tcp to ports 80,443Outbound rules:1 allow
Demo
基于上面的架构及核心概念,我们通过一个简单的例子,直观的感受下 Calico 的网络管理。
Calico 以测试为目的集群搭建,步骤很简单,这里不展示了, 大家可以直接参考 Github: https://github.com/projectcali ... ME.md
这里默认已经有了 Calico 网络的集群,IP 分别是:192.168.99.102 和 192.168.99.103
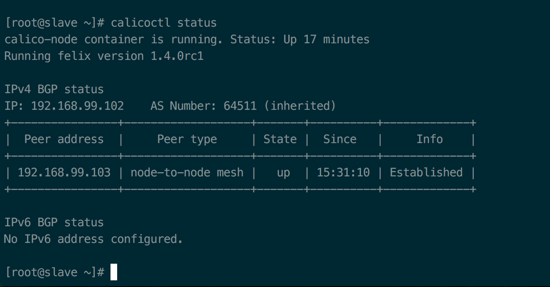
calicoctl status 截图:
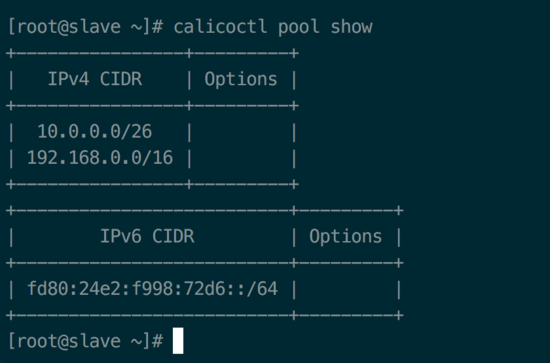
同时,已经有两个 IP Pool 创建好,分别是:10.0.0.0/26 和 192.168.0.0/16
calicoctl pool show 截图:
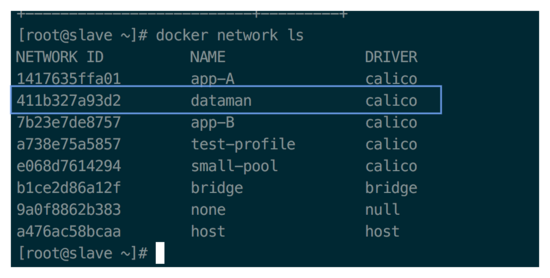
当前集群也已经通过使用 calico driver 和 IPAM 创建了不同的 docker network,本次 demo 只需要使用 dataman
docker network ls 截图:
calicoctl profile show 截图:
下面我们使用 dataman 这个网络,在两台 slave 机器上各启动一个容器:
数人云 下发容器的 Marathon json file:
{
"id": "/nginx-calico",
"cmd": null,
"cpus": 0.1,
"mem": 64,
"disk": 0,
"instances": 2,
"container": {
"type": "DOCKER",
"volumes": [],
"docker": {
"image": "nginx",
"network": "HOST",
"privileged": false,
"parameters": [
{
"key": "net",
"value": "dataman"
}
],
"forcePullImage": false}},
"portDefinitions": [
{
"port": 10000,
"protocol": "tcp",
"labels": {}
}]
}
两台 slave 容器 IP 截图:
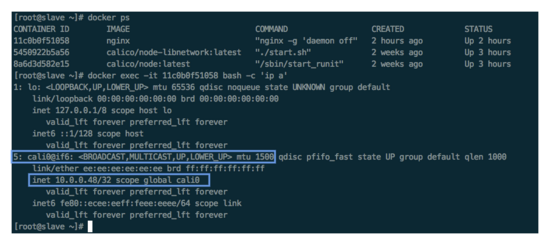
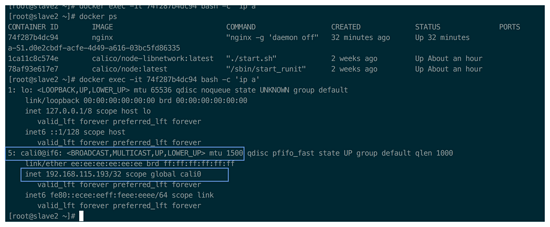
从上图可以看出,两个 slave 上的容器 IP 分别是:slave 10.0.0.48, slave2 192.168.115.193
Slave 容器连通性测试截图:
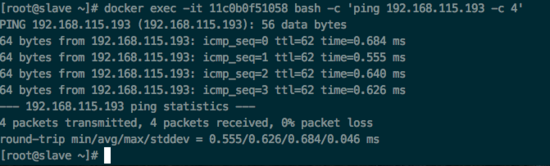
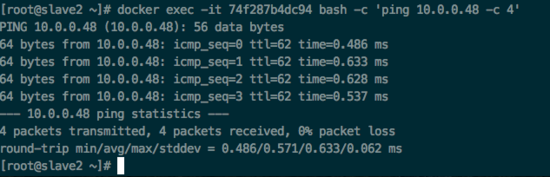
IP 路由实现
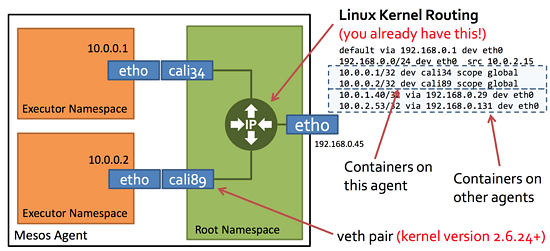
根据上面这个 Calico 数据平面概念图,结合我们的例子,我们来看看 Calico 是如何实现跨主机互通的:
两台 slave route 截图:
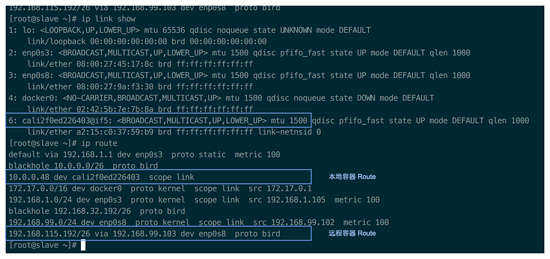
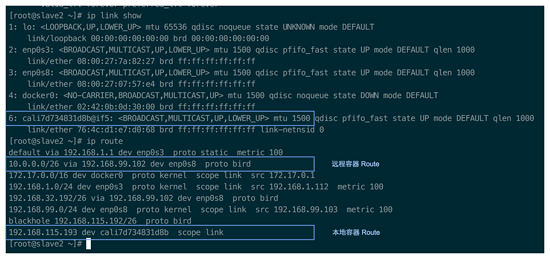
对照两台 slave 的路由表,我们就知道,如果 slave 1 上的容器(10.0.0.48)想要发送数据到 slave 2 上的容器(192.168.115.193), 那它就会 match 到最后一条路由规则,将数据包转发给 slave 2(192.168.99.103),那整个数据流就是:
container -> kernel -> (cali2f0e)slave 1 -> one or more hops -> (192.168.99.103)slave 2 -> kernel -> (cali7d73)container
这样,跨主机的容期间通信就建立起来了,而且整个数据流中没有 NAT、隧道,不涉及封包。
安全策略 ACL
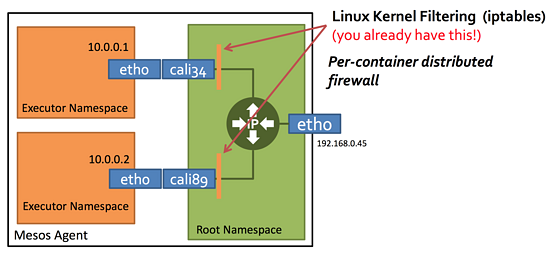
Calico 的 ACLs Profile 主要依靠 iptables 和 ipset 来完成,提供的是可针对每个容器级别的规则定义。
具体的实现我们可以通过 iptables 命令查看对应的 chain 和 filter 规则, 这里我们就不展开讨论了。
Contiv
Contiv 是 Cisco 开源出来的针对容器的基础架构,主要功能是提供基于 Policy 的网络和存储管理,是面向微服务的一种新基架。
Contiv 能够和主流的容器编排系统整合,包括:Docker Swarm, Kubernetes, Mesos and Nomad。
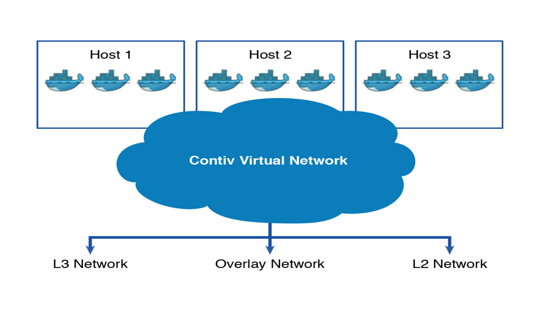
如上图所示,Contiv 比较“诱人”的一点就是,它的网络管理能力,既有L2(vlan)、L3(BGP), 又有 Overlay(VxLAN), 而且还能对接 Cisco 自家的 SDN 产品 ACI。可以说有了它就可以无视底层的网络基础架构,向上层容器提供一致的虚拟网络了。
Contiv netplugin 特性
多租户网络混部在同一台主机上
集成现有 SDN 方案
能够和非容器环境兼容协作,不依赖物理网络具体细节
即时生效的容器网络 policy/ACL/QoS 规则
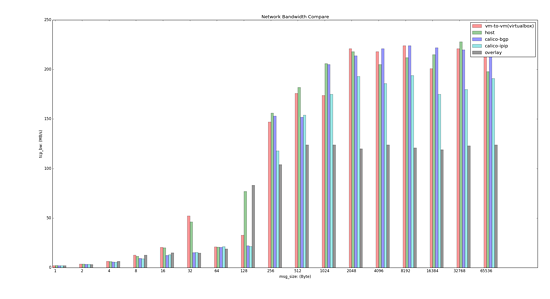
网络方案性能对比测试
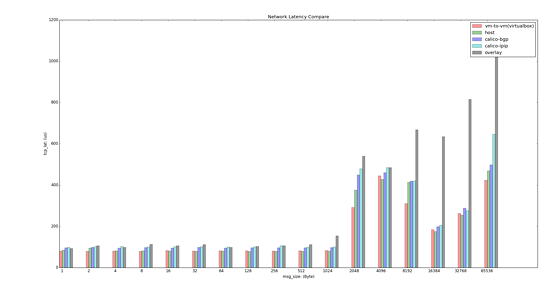
最后附上我们使用 qperf 做的简单性能测试结果,我们选取了 vm-to-vm, host, calico-bgp, calico-ipip 以及 swarm overlay 进行了对比。
其实 Contiv 也测试了,但是因为 Contiv 的测试环境和其他方案使用的不同,不具有直接可比性,所以没有放入对比图里。 直观感受就是基于 OVS 的方案确实不理想,后面有时间会统一环境继续进行测试对比,包括 Contiv 的 L3/L2方案以及引入 MacVLAN、flannel 等。
测试环境:VirtualBox VMs,OS:Centos 7.2,kernel 3.10,2 vCPU,2G Mem。
带宽对比结果如下:
时延对比结果如下:
qperf 命令:
# server 端$ qperf
client 端
持续 10s 发送 64k 数据包,tcp_bw 表示带宽,tcp_lat 表示延迟
$ qperf -m 64K -t 10 192.168.2.10 tcp_bw tcp_lat
从 1 开始指数递增数据包大小
$ qperf -oo msg_size:1:64k:*2 192.168.2.10 tcp_bw tcp_lat
总结
随着容器的落地,网络方案必将成为“兵家”必争之地,我们 数人云 是轻量级 PaaS 容器集群管理云平台,在网络方案选择上的考虑是:
性能,Calico 和 MacVLAN 都有着不错的表现;Contiv L3(BGP) 理论上性能也不会差;
普适性,Calico 对底层的基本要求就是 IP 层可达;MacVLAN 不适应于公有云;Contiv 对底层的兼容性可能更好;
可编程性,保证整个网络管理过程能够程序化、API 化,这样方便集成到产品里,不需要手动运维;Calico 和 Contiv 都有相应的模块;
未来发展,这个就是我说的“站队”,Docker 的 CNM 和 CoreOS、K8S 的 CNI,现在还看不清,Calico 和Contiv 都是支持的;
综上,个人推荐关注和尝试下 Calico 或者 Contiv 做为容器的网络方案,有问题或者收获,欢迎随时交流分享。
QA
Q1:从你发的 Marathon json 文件来看,你们是对 mesos 底层的网络做了扩展吗?容器网络通过"parameters"传递下去的吗?
A: 就是利用 Marathon 支持的 Docker parameters 下发,等同于 docker run —net dataman xxx
Q2:felix 根据配置的 pool 地址段配置路由,bgp client 通告路由?请问 bgp 的邻居关系是怎么建立的?是依靠 etcd 里的信息?
A1: 是的,felix 配置本地 kernel 路由,bgp client 负责分发路由信息
A2: bgp 小规模部署采取 mesh 方式建立,所有节点互联 n^2 的联系,大规模部署推荐 部署一个或多个 BGP route reflector,专门负责路由信息分发。
Q3:Weave有UDP和Fast Data Path两种方式,Fast Data Path应该用的也是vxlan,关于这一块不知道有没有和其余采用vxlan的方案做过性能对比测试?
A: 不好意思,Weave 的我们都没有测试,但看到有人测过,好像 Fast Data Path 也是没有 Calico 和 Macvlan 好的。
Q4: 请问在dataman这个网络中路由信息是如何更新的?我们知道BGP是可以自己发现收敛网络的,那么在网络控制层面是如何设计的?
A1:随着使用 dataman 这个网络的容器的添加或者删除,felix 负责更新本地路由,BGP client 负责向外分发;
A2: calico 的 BGP 和广域网的 BGP 还是有不同,它只是使用 private AS num,相对自治,网络控制层面都是可以程序控制的。
Q5:请问calico如何解决多租户里地址冲突的问题?
A: 多租户容器混部在同一主机上时,所使用的 network 最好不要用同一个 Pool 里的就好,这样就不可能有冲突了;
Q6:如果集群的容器很多,那么相应的路由表的规则也会增多,这样会不会对网络性能造成影响?
A: 网络性能不会有太大影响,因为容器多流量多网络压力本来就大,倒是会增加系统负载,毕竟要配置路由规则,同步网络信息;这部分我们也很关心,但还没有具体的测试结果;
Q7 : 还有就是路由信息是存放在etcd中吗?如何保证路由表的读取性能和维护路由表的信息更新?
A1:生效的路由肯定是本地的,endpoint 等信息是在 etcd 的;
A2: 这两个问题都是 calico 自身要解决的问题,这部分我们也很关心,但还没有具体的测试结果;
Q8:calico基于iptable做转发,的确有性能上的优势。但缺点是随着容器数量的增长(比如1w),转发规则也按比例增长,对于庞大的路由表管理,会是个潜在问题吗?
A:我看到有人,好像是宜信的,测试过 10W,对于单台主机我觉得差不多算是上限了,但我们还没有具体的测试结果;
Q9:目前你们实际生产上跑过多少容器基于calico?
A:目前处于实验性阶段,只在内部测试系统小规模测试中。。。
Q10:Calico下跨多个路由 hop 的情况,中间路由不需要学习这么多的容器路由表吗?
A:不需要,中间过程是依赖节点之间原有的网络建设的,只要两个节点互通,所有的 hop 都不需要知道 calico 内部的容器路由信息;
Q11:还有一个问题,就是网络管理问题。目前从设备厂商网站看有几个支持vxlan控制器的。这些控制器能不能与容器ovs协同? 目前来看我们这里买国外产品还是比较困难的
A:这个肯定是问题,我觉得作为平台方,我们能做的很少,如果要改变,肯定是要 SDN 设备厂商发力,就像是各家都会去为 Openstack 适配设备提供 driver 一样,但是也需要 Docker 或者说容器编排系统能做到如同 Openstack 那样的行业标准级。
Q12:calico能和flannel整合么?coreos上kubelet里同时出现了calico和flannel
A:calico 在 Docker Con 2016 应该是高调拥抱了 flannel,两个整合出了一个叫 canal 的项目,有兴趣可以去找找看。
Q13: 我想问一下老师,你这vxlan的标签是calico打的对吧?
A:Calico 没有 vxlan,Calico 的 tag 会对应到 ipset,iptables 用来 match filter 规则。
Q14:请问宿主记有多个网卡怎么搞?
A:宿主机多网卡 目前 mesos 和 calico 都不支持,但是 数人云 同时也在考虑接管方式,目前还没有成熟的东西可以分享。
Q15:尝试过把bird换掉吗,用这个的貌似不是很多
A:bird 属于 calico 的组件选择,我们目前阶段还是不会对开源组件进行深度定制的。
Q16:rr和L3之间试过不用bgp吗
A:还没有,我们这边还相对早期,没有深度改装和调优;你们如果有相关想法欢迎一起交流下。


